|
Comportement et efficacité en recherche d'information sur Internet chez des adultes en formation professionnelle David Guigui, François-Marie Blondel Introduction Selon les enquêtes du CREDOC, la pénétration des ordinateurs dans les foyers avec, dans son sillage, la connexion au réseau Internet, a connu une appréciation significative au cours des dix dernières années (Bigot & Croutte, 2008). En juin 2008, plus de la moitié des français âgés de plus de 18 ans disposaient d'une connexion à Internet à leur domicile. Cependant, comme le notent les auteurs, « des disparités conséquentes persistent selon les catégories sociales » puisque « plus de huit diplômés du supérieur sur dix (82 %) accèdent à la Toile depuis leur domicile, contre un non-diplômé sur quatre (27 %) » (op. cit. p. 54). Chez les jeunes et les plus diplômés, Internet commence à prendre une place importante comme source d'informations, y compris pour suivre l'actualité (p. 161). Si pour une partie significative de la population, Internet est devenu un des moyens privilégiés d'accéder à l'information, il importe de s'interroger sur la manière dont les internautes cherchent – et trouvent – les informations qui les intéressent. Dans la panoplie des outils et des services qui sont mis à leur disposition, les moteurs de recherche occupent une place prépondérante, devenant pour beaucoup la première étape de leurs recherches. Il ne fait pas de doute que le recours à un moteur de recherche est devenu une habitude pour de nombreux utilisateurs du web. Mais pour autant ce recours est-il toujours efficace ? Les internautes ont-ils une maîtrise suffisante des outils pour aboutir dans leurs recherches ? Que font-ils en cas d'échec ? Connaissent-ils suffisamment les moteurs pour en interpréter correctement les résultats ? Comment ces connaissances et ces savoir-faire sont-ils répandus dans la population ? Quels rapports y a-t-il entre l'âge, le niveau d'études, les usages d'Internet et les comportements de recherche d'information ? Ces questions, dont les premiers travaux remontent aux années 90, conservent une réelle acuité avec les rapides évolutions que connaît le secteur des moteurs et de la recherche sur Internet. Non seulement la diversité des usages s'est fortement réduite au bénéfice de Google [1], mais de surcroît les fonctionnalités de ce moteur et celles de ses concurrents ont sensiblement évolué. Si les grandes enquêtes permettent de dégager des tendances générales, des travaux plus centrés sur des utilisateurs particuliers permettent de mieux rendre compte des pratiques et des comportements. C'est pour ces raisons que nous avons mené une étude exploratoire sur les comportements d'adultes dont nous allons présenter, dans la suite, le contexte, la méthode et les résultats [2]. La recherche d'information sur Internet par les utilisateurs Le développement des moteurs de recherche à la fin des années 90 a suscité de nombreux travaux sur leurs fonctionnalités et leurs utilisations. S'intéressant plus particulièrement aux recherches sur les utilisations qui en sont faites, Assadi et Beaudouin (2002) font une distinction entre les approches « centrées sur les moteurs », le plus souvent fondées sur l'analyse de traces (logs), et les approches « centrées utilisateur », plus expérimentales, qui reposent sur l'observation d'utilisateurs dans des tâches de recherche d'information. Ainsi, comme l'ont mis en évidence Holscher & Strube (2000) il existe des différences importantes entre des utilisateurs « experts » dont les stratégies combinent recours à des moteurs ou des annuaires et navigation sur des sites particuliers, et des utilisateurs « novices » qui formulent un plus grand nombre de requêtes, éprouvant des difficultés à trouver la « bonne » formulation pour leurs requêtes. Mais, dix années après cette première analyse, peut-on encore observer les mêmes différences alors que les pratiques de recherche ont largement évolué ? Nous faisons l'hypothèse que des nuances sont apparues entre ces deux extrêmes, experts et novices, laissant place à des catégories intermédiaires d'utilisateurs. De nombreux facteurs peuvent influencer la manière dont les utilisateurs recherchent des informations. À l'occasion d'une revue des méthodes employées dans ces recherches, Martzoukou (2004) rappelle trois grandes catégories de facteurs qui ont été étudiées : les connaissances acquises par la pratique (user experience), les styles cognitifs et les différences socioculturelles. Parce qu'elles sont difficiles à mettre en place, les études qui reposent sur l'observation d'utilisateurs se sont intéressées à certaines catégories de la population, en ciblant plus particulièrement les étudiants, les élèves et les professionnels de l'information. Cherchant à approfondir la notion de fracture numérique [3], Hargittai (2002) a observé des utilisateurs ordinaires et constate une très grande variation dans les moyens de chercher des informations. Allant au delà des différences qui s'expliquent par les possibilités d'accès à Internet, l'auteur met en évidence un deuxième niveau de fracture dans lequel interviennent principalement les compétences et savoir-faire et les connaissances acquises par la pratique. Dans une étude récente, Van Deursen et Van Dijk (2009) qui se sont intéressés aux compétences générales des utilisateurs ordinaires dans le domaine numérique, ont aussi montré que leurs compétences en recherche d'information sont en général assez peu développées. Comment les utilisateurs actuels qui sont plus nombreux à avoir accumulé une expérience de l'Internet effectuent-ils leurs recherches ? Quelles connaissances et savoir-faire mettent-ils en jeu dans leurs utilisations des moteurs de recherche ? Quelles relations peut-on établir entre leurs pratiques et leurs compétences ? C'est ce que nous avons voulu approfondir dans cette étude exploratoire sur le comportement de recherche d'information d'utilisateurs adultes ordinaires. Méthodologie de l'étude Nous avons choisi d'étudier de manière assez précise comment des utilisateurs résolvent des tâches de recherche d'information sur des questions générales. Population étudiée Le choix de la population étudiée a été en partie dicté par les possibilités d'observation dont nous pouvions disposer. Il s'est fixé sur des adultes en formation professionnelle. Parmi les groupes de stagiaires à qui nous avons proposé de participer à cette étude, nous avons retenu dix volontaires, cinq stagiaires inscrits en formation qualifiante de dessin industriel assisté par ordinateur et cinq autres inscrits dans un stage de remise à niveau. Ils se répartissent en deux niveaux de formation, le niveau IV concerne les titulaires d'un bac ou bac professionnel et le niveau V rassemble des personnes ayant obtenu un CAP ou un BEP ou ayant interrompu leur scolarité en troisième. Déroulement de l'observation La séance d'observation était centrée sur deux tâches successives, la première, sous la forme d'un exercice visant à réduire le nombre de résultats Google et la seconde sous la forme d'une recherche d'information ciblée. Dans un deuxième temps, les stagiaires ont rempli un questionnaire individuel portant sur leurs caractéristiques personnelles et sur leurs pratiques usuelles de l'ordinateur et du web. La séance se concluait par un entretien avec l'observateur au cours duquel il leur était demandé de décrire, de commenter et d'expliquer leurs actions avec, suivant les cas, quelques questions sur leurs connaissances et leurs attitudes. Les tâches de recherche d'information Pour ces deux tâches, nous avons choisi des questions peu connotées culturellement ou portant sur des sujets d'actualité suffisamment récente, pour ne pas créer de différence sur le plan de l'âge, des connaissances ou de compétences particulières. Nous avons donc centré les questions de la première tâche sur une recherche ancrée dans la réalité quotidienne, à savoir de rechercher un médecin, et la deuxième sur une recherche d'information sportive, les Jeux Olympiques. La durée initiale prévue pour chaque tâche était d'environ 15 minutes. Au cours de la première tâche, de réduction du nombre de résultats, les stagiaires se voyaient demander d'envoyer une requête au moteur Google avec le seul mot « médecin », puis d'ajouter le nom d'une ville et de changer ensuite le nom de la ville pour obtenir le moins possible de résultats. Ils devaient ensuite remplacer le nom de la ville par un mot quelconque, de manière à réduire encore le nombre de résultats. Enfin ils devaient essayer de réduire encore le nombre de résultats, sans modifier les mots, autrement dit sans effectuer une requête supplémentaire, mais en utilisant un autre moyen. L'objectif de cette activité qui prend la forme d'un défi, est de recueillir des informations sur ce que les utilisateurs perçoivent du fonctionnement du moteur. La deuxième tâche, de recherche d'information ciblée, consistait en une recherche d'informations sur la participation et les résultats d'athlètes français aux Jeux Olympiques d'été, à Pékin en 2008 et à Athènes en 2004. Il s'agissait de trouver le nombre total de médailles obtenues par ces athlètes au cours de la dernière participation, en 2008, puis le nom de deux médaillés olympiques français en judo et en tir à l'arc, en précisant si la médaille était en or en argent ou en bronze. Enfin une dernière question portait sur la composition de l'équipe de France de judo féminine aux Jeux de 2004. Par cette activité, on pouvait espérer observer quelques unes des méthodes que les utilisateurs emploient pour rechercher une information précise. Le questionnaire Le questionnaire, rempli après avoir terminé les deux tâches, comprenait des questions sur leur âge, leur niveau scolaire, la date d'obtention de leur dernier diplôme et le métier qu'ils avaient exercé. D'autres questions visaient à chercher des indications sur leur fréquence d'utilisation de l'ordinateur et d'Internet, et sur les usages ils en faisaient. Les entretiens complémentaires Au cours de l'entretien qui suivait, les stagiaires étaient interrogés sur leurs connaissances d'internet et de l'informatique et dans un second temps sur leur perception de la séance, afin de recueillir leur point de vue, leurs intentions et la mémoire de leurs actions au cours de la recherche d'information. Déroulement des séances Les séances ont toutes été menées sous la forme de séances libres sur le lieu de la formation en présence de l'observateur. La durée des séances n'a pas été limitée a priori mais cette consigne n'a pas été bien perçue par certains participants qui ont déclaré au cours des entretiens, ne pas avoir eu assez de temps. Chaque participant a reçu un « livret de séance » comprenant les énoncés des tâches et des questions et sur lequel il inscrivait ses résultats. Les activités de recherche d'information ont été effectuées avec un ordinateur de bureau connecté à Internet équipé du système d'exploitation Windows XP et du navigateur Mozilla Firefox 3.5. À l'issue de chaque séance, l'historique du navigateur a été systématiquement nettoyé et le cache du navigateur vidé. La recherche d'information a été enregistrée à l'aide d'un outil permettant de capturer les flux vidéo et audio du poste de travail (Camtasia Studio, Techsmith), et les données de navigation ont été extraites en même temps que l'historique de navigation. Tous les entretiens ont été enregistrés et transcrits. Codage des actions À la relecture des enregistrements vidéo des interactions entre les utilisateurs et le navigateur, nous avons codé les actions principales des stagiaires en six grands types : la formulation, le changement ou l'envoi d'une requête, l'exploitation d'un résultat, c'est-à-dire le fait de cliquer sur l'un des liens proposés par le moteur de recherche, l'exploration d'une page, c'est-à-dire le fait de dérouler une page d'un site, et la navigation, soit le passage d'une page de site à une autre (voir figure 1). À chaque action, a été associée une date, exprimée en heures, minutes et secondes, l'outil utilisé pour cette action, une description, et, s'il y avait lieu, le contenu de la requête ou l'adresse URL de la page et le type de page, à savoir requête, résultat et visite. Les pages affichées ont été réparties en trois catégories, requête qui regroupe les pages du moteur Google sur lesquelles les stagiaires formulent leurs requêtes, résultat qui rassemble les pages affichant les résultats rendus pour une requête donnée, et visite qui regroupe les pages des sites visités. Nous avons également codé l'utilisation de la souris. Chaque clic de souris, qui correspondait soit à une sélection de texte, soit à l'envoi d'une requête ou encore à une insertion dans un champ de recherche, a été comptabilisé. Tous ces clics ont été considérés comme des opérations élémentaires et nous ont permis de mesurer par la suite, une sorte de niveau d'activité en fonction du temps.
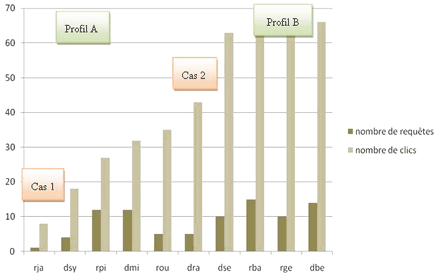
Figure 1 : exemple de codage pour un stagiaire. [Zoom] Résultats généraux Aspects démographiques et usages Sur la dizaine de participants âgés de 23 à 57 ans, neuf étaient des hommes, la moyenne d'âge étant de 39 ans. Parmi eux, on comptait quatre titulaires d'un baccalauréat professionnel, un titulaire d'un baccalauréat général, un d'un BEP, et deux d'un CAP ; enfin un stagiaire avait interrompu sa scolarité en 3e et un autre n'avait aucun diplôme. La plupart indiquait utiliser régulièrement l'ordinateur. Sept ont déclaré avoir un ordinateur à leur domicile avec un accès internet et trois disaient en avoir plus d'un. Huit sur dix ont indiqué l'utiliser au moins une fois par semaine. Par contre, quand nous leur avons demandé d'estimer leur propre niveau, huit se sont qualifiés débutants, ce qu'a confirmé une observation faite au cours des entretiens : trois seulement ont su dire ce qu'était un navigateur web. Durées et habiletés pratiques Pour traiter les deux tâches, les durées ont été variables, entre 27 et 49 minutes, soit une variation du simple au double. L'aisance dans l'utilisation du matériel de saisie, souris et clavier, n'a pas semblé intervenir de manière significative dans ces différences. En effet, le travail n'a pas posé de problèmes particuliers de ce point de vue même si des différences notables ont été observées dans la saisie des requêtes au clavier. Deux stagiaires n'utilisaient qu'un seul doigt pour la saisie, deux autres utilisaient deux doigts, quatre utilisaient six doigts et les deux derniers utilisaient leurs dix doigts. Nous avons observé quelques erreurs de frappe ou d'orthographe dans la saisie mais ces erreurs n'ont pas occasionné d'obstacles à l'accès à l'information contrairement à ce qu'a observé Hargittai (2006) sur une population plus importante. Première tâche, réduction du nombre de résultats : Google, un moteur sémantique ? Pour cette tâche, les durées ont été assez échelonnées, les stagiaires ayant mis entre 9 et 23 minutes. La réussite globale, c'est-à-dire l'obtention d'un nombre de résultats inférieur a été assez bonne. Tous les stagiaires ont assez bien compris les questions posées et ont proposé des méthodes permettant d'y répondre plus ou moins efficacement. Mais les méthodes qu'ils proposaient témoignaient d'une perception du fonctionnement du moteur Google qui restait assez vague et partiellement erronée. Les stagiaires ont entré les noms de villes qu'ils connaissaient pour être plutôt petites et donc susceptibles de compter peu de praticiens. Plusieurs ont exprimé le fait que le nombre de résultats rendus par le moteur correspondait au nombre de médecins dans la ville. Quand ils ajoutaient un nom de ville à la suite du mot médecin, plusieurs stagiaires semblaient se comporter comme si le moteur interprétait la requête comme « trouver des informations sur les médecins de la ville ». Ce lien entre les informations retournées par le moteur de recherche et la présence de médecins a pu être relevé à plusieurs reprises dans les commentaires ou les entretiens. Ainsi, deux stagiaires, DSY et DRA [4] ont exprimé l'idée que les résultats rendus par le moteur étaient contestables, car ils connaissaient les villes en question et savaient « qu'il ne pouvait pas y avoir autant de médecins dans ces villes ». Ainsi, à propos du nombre de résultats de la requête « médecin B » [5] (environ 28 000), DSY a commenté : « y'a quand même pas 28 000 toubibs à B, puisque déjà la population elle fait beaucoup moins. » À la deuxième question demandant d'ajouter un mot qui ne soit pas un nom de ville, ils se sont limités pour la plupart à un registre proche de la médecine. Un seul stagiaire, ROU, a essayé plusieurs mots sans aucun rapport avec ce registre, comme « médecin marteau », montrant ainsi une certaine intuition du rôle des mots de la requête dans la présentation des résultats par le moteur. En considérant à la fois les requêtes et les commentaires des utilisateurs, il apparaît assez nettement que la majorité d'entre eux semblait considérer que le moteur utilisait la sémantique des termes de leur requête pour construire ses réponses. Deuxième tâche, recherche d'information ciblée Dans cette deuxième tâche, les durées ont varié de 7 à 31 minutes, soit un rapport proche de 1 à 5, beaucoup plus important que pour la première tâche. Les trois questions posées (nombre de médailles en 2008, noms des médaillés en judo et en tir à l'arc en 2008, composition de l'équipe de judo féminine en 2004) comportaient au total 13 items de réponse. La réussite dans cette tâche a été plus mitigée que pour la première tâche. Les réponses trouvées variant de 6 à 13 items, avec une plus grande dispersion sur la dernière question, plus difficile, où la variation s'étendait de 0 à 6 items. Les durées de traitement de cette question étaient d'ailleurs assez étalées, variant de 2 à 13 minutes. La compréhension des questions ne semblait pas être en cause, aucun stagiaire n'ayant manifesté de difficulté à interpréter les questions posées. Des requêtes plutôt longues, peu de pages consultées Le nombre de requêtes formulées par utilisateur a varié de 1 à 14, avec un total de 83 requêtes pour les 10 participants. Dans cet ensemble, on a distingué assez nettement deux groupes, le premier ayant formulé entre 4 et 6 requêtes et le second entre 10 et 14 requêtes, et un cas particulier, un stagiaire qui n'a effectué qu'une seule requête. Les requêtes étaient en général assez longues. Le nombre de mots par requête était élevé, en moyenne 6 mots par requête. Cette observation révélant un comportement assez différent de ce qui a été rapporté par plusieurs auteurs notamment Boubée et Tricot qui ont observé un nombre de mots inférieur chez des lycéens et des collégiens (Boubée & Tricot, 2007). En étudiant les formes que prennent les requêtes à partir de la typologie établie par Caroline Ladage à propos d'une étude des requêtes d'élèves en fin de scolarité élémentaire, nous avons constaté que la proportion de requêtes sous forme de phrases ou de propositions grammaticales était comparable (10 % des requêtes) (Ladage, 2007). En revanche les résultats étaient assez différents pour les autres types de formulations. Aucun stagiaire n'a formulé de requête sous forme de question, contre 27 % de la population de l'étude de Ladage. A contrario, 90 % des requêtes ont pris la forme de mots clés, contre un peu plus de la moitié seulement dans l'étude précitée. Enfin, il faut noter le cas d'un stagiaire qui n'a formulé qu'une seule requête de 12 mots, sous la forme d'une proposition grammaticale : « nombre de médailles obtenues par les athlètes français aux JO de 2008. » Cette unique requête lui a d'ailleurs suffit pour trouver, par navigation dans les résultats, toutes les réponses aux questions demandées (cf. RJA infra). Quant à l'exploitation des liens présentés par le moteur Google, elle s'est souvent limitée aux premiers résultats affichés. Plus d'un tiers des sites visités (34 sur les 87 sites visités) correspondaient au premier lien de la page de résultats et plus de la moitié (56 sur 87) aux deux premiers liens. Cette observation est conforme à celle qu'avaient effectuée Van Deursen et Van Dijk dans leur étude sur les compétences d'utilisateurs ordinaires. La grande majorité des utilisateurs n'utilisent que les tout premiers liens. Un moteur au fonctionnement obscur Nous avons observé que les stagiaires éprouvaient de réelles difficultés à interpréter les résultats affichés par le moteur de recherche. Par exemple, dans la troisième question portant sur l'équipe féminine de judo de 2004, après avoir envoyé la requête « jeux olympiques 2004 », plusieurs stagiaires n'ont pas compris pourquoi le moteur renvoyait des pages avec des informations sur les Jeux de 2008. Leurs réactions allaient de l'étonnement à l'agacement, voire à l'énervement, un stagiaire lâchant « c'est quoi ce travail », ou un autre « mais c'est pas normal », laissant poindre une réaction de rejet. Ces réactions pouvant être cause d'échec en cours de recherche ou d'abandon. Ainsi au cours de l'entretien qui a suivi sa recherche, un stagiaire (RGE) a déclaré qu'il lui arrivait souvent d'abandonner une recherche quand il ne trouvait pas ce qu'il voulait : « franchement quand ça me fait des trucs comme ça, je m'en vais, quand je cherche des données, y me donne je sais pas quoi, franchement ça me prend la tête j'arrête, ..., ça me le fait souvent ça en plus. » Ces résultats sont proches de ceux de Ravestein, Ladage et Joshua (2007), qui, à propos de recherches effectuées en milieu scolaire, ont montré que la plupart du temps, les utilisateurs faisaient une grande confiance au moteur de recherche pour le résultat mais n'avaient qu'une idée très vague de la manière dont il fonctionne. Une difficulté à extraire des informations dans les documents consultés L'observation et les entretiens ont aussi mis en évidence une tendance à rechercher une réponse complète dans une seule page. Ainsi, dans la troisième question où les résultats du moteur affichaient plutôt la composition de l'équipe de 2008 que celle de 2004, seuls trois stagiaires ont cherché à déduire dans les informations disponibles (le palmarès des athlètes) les noms de ceux qui avaient participé aux Jeux de 2004. Ces informations, partielles, permettaient de répondre en partie à la question posée. Cette attitude de la plupart des participants, qui consistait à chercher une information complète, est en partie liée à une difficulté à extraire la réponse de plusieurs documents. Ce qu'ils ont exprimé assez clairement dans les entretiens : Elle peut aussi être induite par le classement des résultats par le moteur qui privilégie les pages les plus « populaires » : Des effets possibles de la tâche Une partie des comportements observés peut aussi s'expliquer par le type de recherche proposé aux utilisateurs, notamment la première tâche, assez éloignée de ce qu'ils ont l'habitude de faire. Les conditions particulières de cette activité, encadrée et observée, ont pu également modifier leurs comportements habituels. Au cours des entretiens, nous avons pu constater que plusieurs stagiaires ont cru devoir se presser ou ont jugé que les conditions étaient défavorables à leur recherche. Ainsi, une stagiaire a exprimé explicitement avoir été perturbée dans sa recherche : Esquisse de profils d'utilisateurs Si nous avons pu constater des similitudes entre tous les stagiaires déterminant ainsi un profil d'ensemble général, il apparaît cependant des différences importantes dans leurs comportements. Essayant de caractériser ces différences, nous nous sommes intéressés au nombre d'actions qu'ils ont effectuées durant la tâche de recherche ciblée. Un bon indicateur de l'activité des stagiaires nous a été fourni par le nombre de clics de souris, car nous avons pu constater qu'il était directement proportionnel au nombre d'actions effectuées. Ce nombre de clics variait de 8 à 66, faisant apparaître clairement deux modes. Le premier correspondant à des stagiaires effectuant peu d'actions, entre 18 et 35, et un second en effectuant beaucoup plus, entre 63 et 66 (Figure 2). Deux stagiaires étaient un peu à part, le premier par son nombre réduit d'actions (RJA) et le second par son nombre réduit de requêtes, comparé à son nombre d'actions (DRA) ; nous les avons donc considérés séparément. Ce critère purement quantitatif avait l'avantage de séparer nettement deux populations. De ce point de vue, il s'est avéré plus discriminant que le nombre de requêtes ou le nombre de pages visitées. On pourra aussi constater sur la figure 2 que le nombre de requêtes n'est pas toujours en relation directe avec le nombre d'actions. Nous allons développer ci-dessous ces deux profils d'utilisateurs et les deux cas particuliers.
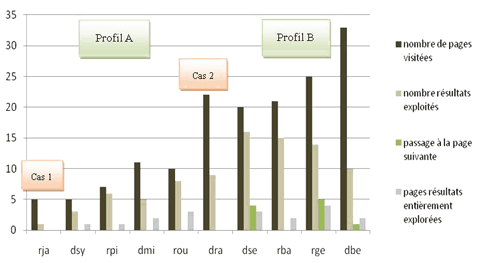
Figure 2 : nombre de requêtes et nombre de clics. Profil A : un groupe peu actif et effectuant peu de requêtes Les quatre stagiaires de ce groupe ont effectué moins d'actions que la moyenne – entre 18 et 34 actions – et aussi moins de requêtes – entre 4 et 6 – sauf un stagiaire qui en a effectué 12. Le nombre de mots entrés par requête se situait dans la moyenne, entre 6 et 8 mots, et la plupart des requêtes étaient rédigées sous la forme de mots clés. Ces stagiaires ont peu utilisé les suggestions orthographiques, de 1 à 2 fois, se situant dans la moyenne. L'exploitation des résultats du moteur a été assez faible. En effet, le nombre de pages de résultats entièrement explorées a varié de 1 à 3 et aucun stagiaire n'est allé consulter la deuxième page de résultats. Nous avons observé un assez faible recours à la navigation ; la navigation au sein d'un site ne dépassait pas deux pages. Un seul stagiaire a utilisé un moteur de recherche interne à un site.
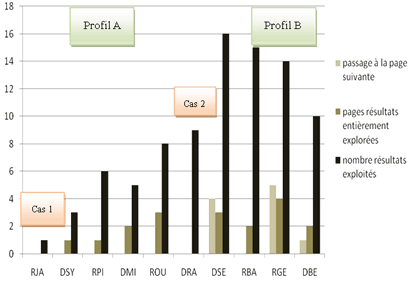
Figure 3 : exploration et exploitation des résultats, La réussite de ce groupe a été plus faible que la moyenne ; trois stagiaires ont répondu à 7 items sur 13, et le quatrième à 6 items. Mais ce dernier stagiaire a eu la démarche d'extraire des informations partielles pour répondre à la question discriminante et donc de construire sa réponse. Les membres de ce groupe étaient âgés de 34 à 57 ans. Ils avaient un usage moins régulier de l'informatique. Deux d'entre eux, ont déclaré ne pas avoir d'ordinateur chez eux et en utiliser rarement. Ils déclaraient ne se servir d'un ordinateur que pour un usage pratique et se définissaient comme des utilisateurs débutants. Aucun d'eux ne connaissait la différence entre un navigateur et un moteur de recherche. Plusieurs ont marqué leur incompréhension face au comportement du moteur de recherche et manifesté de l'agacement de voir le moteur de recherche ne pas leur fournir la réponse attendue. Enfin, tous ont affirmé avoir tendance à chercher les informations plutôt « par étapes », et n'ont pas exprimé l'idée qu'ils pouvaient tout trouver directement. La population de ce groupe, était donc globalement plutôt âgée, peu familière du web et des outils informatiques ; certains ont même exprimé une réelle appréhension vis-à-vis de ces outils. Ces utilisateurs n'étaient pas vraiment convaincus d'être capables de trouver sur le web l'information qu'ils recherchaient. Profil B : un groupe plus actif, effectuant plus de requêtes Ce groupe comptait quatre stagiaires qui ont effectué un assez grand nombre d'actions, entre 63 et 66, et aussi un assez grand nombre de requêtes, entre 10 et 14. L'utilisation des suggestions orthographiques a été assez similaire à celle du groupe A. Le recours aux suggestions de Google y était moins fréquent, à l'exception notable d'un stagiaire qui les a utilisées 8 fois. Les membres de ce groupe ont exploité beaucoup plus de résultats du moteur, de 10 à 16, alors que ceux du groupe A en ont exploité de 3 à 8. Leur exploration des pages de résultats du moteur est aussi plus importante, ainsi la consultation de la page suivante de résultats varie de 0 à 5.
Figure 4 : exploitation des résultats du moteur. Ils ont également visité un assez grand nombre de sites, dont des sites liés au sport, des sites spécialisés en judo ou des sites de la presse sportive. L'usage de la navigation y était plus important que pour le groupe A, avec un nombre de pages visitées variant de 4 à 11. Leur réussite était relativement bonne, un stagiaire réussissant à répondre à toutes les questions, et deux répondant à 10 items sur 13. Deux stagiaires ont aussi eu la démarche d'extraire des informations partielles pour la dernière question. Ces quatre stagiaires étaient relativement jeunes, entre 23 et 35 ans, et ils utilisaient l'ordinateur et consultaient le web plus fréquemment. Les utilisations qu'ils déclaraient étaient aussi plus nombreuses, et plus diversifiées que pour le groupe A. Ainsi, trois d'entre eux ont cité l'utilisation de l'ordinateur pour des jeux, des loisirs ou la fréquentation de sites marchands. Ils avaient quelques connaissances du web et de l'informatique, puisqu'ils ont su, même si c'était avec des erreurs, décrire sommairement un navigateur web et en citer un, voire deux. Nous avons aussi pu constater qu'un stagiaire se referait à l'adresse URL d'un site Internet pour choisir les pages qu'il visitait. Enfin dans la description de leurs motivations, tous sans exception ont affirmé vouloir trouver les résultats du premier coup ou ont expliqué qu'ils recherchaient un résultat plutôt complet dès le départ et qu'ils n'essayaient pas de procéder par étapes. Ce groupe correspondait donc à une population plutôt jeune, relativement habituée au web et à Internet, et exprimant peu d'appréhension à utiliser ces outils. Ils ont eu une activité plus importante sur tous les plans, une réussite globalement plus élevée et une motivation assez clairement assumée de vouloir trouver tous les résultats sur une même page. Deux cas particuliers Un adepte de Wikipédia Son activité a été faible, 8 clics en tout et pour tout, 2 pour la première question, 4 pour la deuxième et 2 pour la troisième. Il n'a effectué qu'une seule requête, pour traiter la première question et a navigué pour chercher les réponses aux questions suivantes. En conséquence, la durée qu'il a consacrée à cette tâche a été très réduite puisqu'il a mis 6 minutes 50 secondes pour l'ensemble, soit trois fois moins que la moyenne. Il n'a utilisé ni moteur de recherche interne ni champ de recherche du navigateur, et n'a navigué que 4 fois. Il n'a exploité qu'un seul résultat : le lien vers le site Wikipédia. Son niveau de réussite est maximum, puisqu'il a répondu à toutes les questions. Ce stagiaire était âgé de 36 ans, un âge situé dans la médiane de notre échantillon, et son utilisation déclarée n'était pas différente de l'ensemble des stagiaires. Mais il a dit avoir plus d'un ordinateur chez lui et aussi avoir un ordinateur avec un accès Internet depuis 10 ans. Par contre il se percevait comme un utilisateur « débutant ». Ses connaissances du web étaient globalement dans la moyenne ; il n'a pas su définir ce qu'était un navigateur et a avoué que tout cela était confus. En revanche, il a dit bien connaître le site Wikipédia, par expérience, comme nous avons pu le constater lors de l'entretien : Il s'agit donc d'un utilisateur d'âge moyen, ayant effectué la tâche en un temps réduit, avec une seule requête, ayant exploité un seul résultat du moteur (Wikipédia) et trouvé les réponses par navigation à partir de ce résultat. Il a déclaré une pratique et une connaissance du web relativement plus élevées que la moyenne. Sa connaissance particulière de Wikipédia lui a permis apparemment de trouver plus facilement des réponses à nombre de questions. Un habitué du web plus âgé Son activité se situait dans la moyenne, avec 43 clics. Il n'a effectué que 5 requêtes. Il n'a utilisé ni moteur de recherche interne, ni champ de recherche du navigateur. Il a, en revanche, exploité un assez grand nombre de résultats, 11, dont 9 pour la dernière question. Il est revenu assez souvent sur les pages de résultats, mais les a peu explorées. Il n'a jamais consulté la deuxième page de résultats du moteur. C'est aussi l'un de ceux qui ont le plus navigué, 11 fois, uniquement sur la deuxième question. Sa réussite a été moyenne puisqu'il a répondu à 6 questions sur 13. En particulier, il n'a pas trouvé des médaillés dont il avait pourtant les photos sous les yeux ; ce qu'il a constaté lui-même au cours de l'entretien lorsque nous avons visionné cette partie de la vidéo. Âgé de 52 ans, il était titulaire d'un BEP mécanique et a travaillé comme tourneur. Il déclarait avoir un ordinateur depuis 13 ans et Internet à son domicile depuis 7 ans. Il a aussi déclaré utiliser l'ordinateur au moins une fois par jour et se définissait comme utilisateur « intermédiaire ». Ses connaissances du web semblaient relativement plus élevées que la moyenne puisqu'il a été capable de citer deux navigateurs : Internet Explorer et Mozilla Firefox. Il a aussi parlé de Wikipédia, mais pour dire qu'il n'était pas fiable. Il s'agissait donc d'un utilisateur plus âgé, ayant formulé peu de requêtes et ayant peu navigué mais ayant exploité un nombre important de résultats. Il a déclaré une pratique et une connaissance du web relativement plus élevées que la moyenne. Mais son expérience et ses connaissances ne lui ont pas suffit pour trouver les réponses à toutes les questions. Conclusion L'observation instrumentée d'un petit groupe de personnes d'origine sociale et professionnelle assez homogène nous a permis de dégager quelques traits caractéristiques des comportements d'utilisateurs ordinaires. Si l'essentiel des résultats reste conforme à ce que l'on a pu trouver dans des études récentes, malgré une assez grande variabilité individuelle, nous avons pu constater que la formulation de requêtes s'est caractérisée par un plus grand nombre de mots, de 6 à 7 mots par requête, soit au moins le double de ce qui est rapporté dans les études générales. Pour cette dizaine d'utilisateurs, il apparaît que l'âge a eu une réelle incidence sur l'activité dans tous les aspects de la recherche : nombre de requêtes effectuées, nombre de résultats exploités ou encore nombre de pages visitées. De même que la fréquence d'utilisation des ordinateurs et du web, ou le fait de posséder ou non un ordinateur à son domicile. Il apparaît aussi que les utilisateurs plus jeunes et plus actifs réussissent un peu mieux que les utilisateurs plus âgés et moins actifs. Il n'en reste pas moins que les comportements varient aussi en fonction d'autres facteurs moins faciles à identifier, comme les attentes des utilisateurs face à l'information, ou les représentations qu'ils se font de l'Internet et du web, facteurs que nous n'avons pu qu'entrevoir. Cette étude a également permis de distinguer deux profils d'utilisateurs et de souligner quelques différences dans les pratiques de recherche d'information sur le web. Le cas d'un utilisateur dont les connaissances et les pratiques ne se distinguent pas du reste de la population mais qui connaît plus particulièrement Wikipédia est nouveau et intéressant. N'y a-t-il pas dans cet exemple le signe d'une évolution de certains utilisateurs qui se limitent à quelques sites ou services spécialisés qui offrent des réponses suffisantes pour bon nombre d'interrogations ? David Guigui, François-Marie Blondel, Laboratoire STEF, ENS Cachan / INRP, UniverSud Bibliographie Assadi, H. & Beaudouin, V. (2002). Comment utilise-t-on les moteurs de recherche sur Internet ? Réseaux, 116, 171-198. Bigot, R. & Croutte, P. (2008). La diffusion des technologies de l'information et de la communication dans la société française. Enquête Conditions de vie et Aspirations des Français, Paris : CREDOC. Boubée, N. & Tricot, A. (2007). La formulation de requête, une pratique ordinaire des élèves du secondaire. 6ème colloque international du chapitre français de l'ISKO – International Society for Knowledge Management, Toulouse, 7-8 juin. Hargittai, E. (2002). Second-Level Digital Divide : Differences in People's Online Skills. First Monday, 7 (4). Hargittai, E. (2006). Hurdles to information seeking : Spelling and typographical mistakes during users' online behavior. Journal of the Association for Information Systems, 7(1), 52-67. Hoelscher, C. & Strube, G. (2000). Web search behavior of Internet experts and newbies. In H. Maurer & R.G. Olson (Eds.), Proceedings of the 9th Int. WWW Conference (p. 337-346). Ladage, C. (2007). Apprendre la recherche d'informations sur Internet à l'école : à la découverte du poids des mots. Congrès international AREF 2007 (Actualité de la Recherche en Education et en Formation), Strasbourg. Lelong, B., Thomas, F. & Ziemlicki, C. (2004). Des technologies inégalitaires ? L'intégration de l'internet dans l'univers domestique et les pratiques relationnelles. Réseaux, 127, 141-180. Ravestein, J., Ladage, C. & Joshua, S. (2007). Trouver et utiliser des informations sur Internet à l'école. Problèmes techniques et questions éthiques. Revue Française de Pédagogie, 158, 71-83. Van Deursen, A. & Van Dijk, J. (2009). Using the Internet : Skill related problems in users' online behavior, Interacting with Computers, 21(5-6) 393-402, NOTES [1] Selon AT Internet Institute, le moteur Google vient très largement en tête, avec environ 90 % des parts de visites provenant d'un moteur de recherche, données recueillies en France en mars 2010. [2] Ce travail a été mené par le premier auteur dans le cadre d'un Master de recherche à l'ENS de Cachan. [3] Pour une analyse détaillée et critique de la notion de fracture numérique, on pourra se rapporter au numéro que la revue Réseaux a consacré à ce sujet (n° 127-128, 2004/5-6). [4] Afin de préserver leur anonymat, les noms des stagiaires sont remplacés par des codes et tous les noms propres sont masqués. [5] B est le nom d'une ville proche du lieu de résidence de DSY. ___________________ |